无序关联容器
无序关联容器提供能快速查找(均摊 O(1) ,最坏情况 O(n) 的复杂度)的无序(哈希)数据结构。
无序关联容器有以下几种
- unordered_set:无序集合,键唯一
- unordered_map:无序键值对集合,键唯一
- unordered_multiset:无序集合,键不唯一
- unordered_multimap:无序键值对集合,键不唯一
无序关联容器底层由哈希表实现,下文主要对哈希表进行介绍
哈希表概述
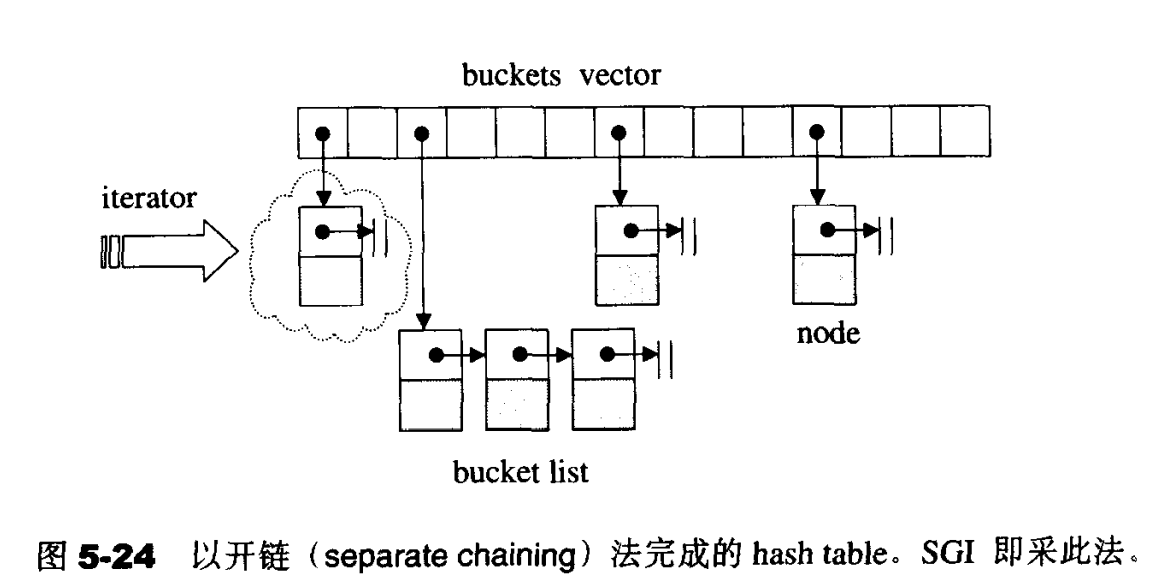
哈希表的基本原理是利用数组可以随机存取的特点,通过哈希函数(hasher)将键(key_type)均匀的映射到数组的下标,这样我们可以很快的通过数组下标快速找到对应的元素
数组中的每个元素称为桶(bucket)
这样会存在两个问题:
- 不同的键映射到了相同的数组下标
- 数组大小是固定的,添加了更多元素之后,如何对数组进行扩容
解决哈希表碰撞
不同的的元素被映射到相同的数组下标,被称为碰撞。解决碰撞有许多种方法
- 开放定址法:哈希冲突时,从冲突的位置按照一定的次序寻找一个空闲的桶。删除元素时需要进行标记,否则会导致查找错误
- 线性探测:依次判断位置为i+1,i+2,i+3,到达最后一个桶时从头开始判断
- 二次探测:依次判断位置为i+1^2,i+2^2,i+3^2
- 链地址法:哈希冲突时,冲突的元素放在链表中。可以理解为数组的每个桶都是一个链表,只是大部分的链表仅包含一个元素
大部分的实现采用链地址法处理冲突
hashtable
哈希表扩容
在一般的实现中,哈希桶的数量为2的次幂,这样可以通过位运算得到元素哈希桶的位置
1
2
| size_type bucket_idx = hasher()(key) % bucket_count();
size_type bucket_idx = hasher()(key) & (bucket_count() - 1);
|
负载因子和初始容量
首先介绍一个负载因子(load factor)的概念:即元素个数除以桶个数。
哈希表一般通过负载因子来指定扩容的临界值。例如负载因子可以设置为0.75。当元素的数量超过bucket_count*load_factor时,会触发扩容操作
哈希表另一个比较重要的概念是初始容量,即初始哈希桶的数量,插入元素较多的情况下可以指定较大的初始容量减少扩容的次数。默认初始容量可以设置为16
扩容步骤
哈希表的扩容也称为重新哈希(rehash),大致步骤如下
- 以2倍的原桶容量(2*old_bucket_count)分配一个新的桶数组
- 遍历原桶数组,计算原桶数组中的每个元素在新桶数组中的位置,并插入到相应的桶中
- 在同数量为2的次幂时,可以将桶中元素分为两部分,这两部分元素在新桶数组中的位置分别是:i和i+old_bucket_count(按照位运算很好理解)
- 所有元素迁移完成之后,释放原桶数组
以下例子是数组+单链表(下文介绍)的重新哈希的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| void do_rehash(size_type new_bucket_count) {
BucketStorage new_buckets = alloc_buckets(new_bucket_count);
SListNode old_head = head_;
buckets_.swap(new_buckets);
head_.next = nullptr;
get_size() = 0;
printf("rehash new bucket count %zu %zu\n", bucket_count(), new_bucket_count);
SListNode* prev = &old_head;
SListNode* first = prev->next;
while (first) {
const key_type& key = get_key(Node::Value(first));
size_type new_bucket_idx = bucket(key);
auto range_res = find_range(key, prev);
RemoveAfter(range_res.first.before, range_res.first.node);
insert_node(new_bucket_idx, buckets_[new_bucket_idx].node_before_begin ? buckets_[new_bucket_idx].node_before_begin : &head_, first, range_res.first.node, range_res.second);
first = prev->next;
}
printf("rehash done. new bucket count %zu\n", bucket_count());
}
|
哈希表的具体实现
哈希表一般有以下几种实现
- 仅数组
- 迭代元素需要遍历整个桶数组
- 元素迭代的顺序与插入顺序无关,与在桶中的位置有关
- 同一个桶内的元素以相反的顺序遍历(在头部插入)
- 数组+单链表:所有的元素用单链表进行串联
- 迭代元素无需遍历整个桶数组,迭代次数与元素次数相同
- 元素的迭代顺序与插入顺序相反(找不到元素时在头部插入)
- 桶的结构中保存链表节点的指针或迭代器(before, node]
- 插入元素时如果更改了某个桶的尾元素node,则需要更新node->next元素所在桶的before指针
- 单链表包含一个伪头结点head_利于实现
- swap时要更新链表头结点的before指针
- 数组+双链表:所有的元素用双链表进行串联
- 迭代元素无需遍历整个桶数组,迭代次数与元素次数相同
- 元素的迭代顺序与插入顺序相同(找不到元素时在尾部插入)
- 桶的结构中保存链表节点的指针或迭代器[begin, node]
- 实现相较数组+单链表简单
说明
- 以上只说明大致思路,具体的实现可能略有不同
- 以上针对元素key唯一的情况,key相同的情况下,相同的key元素在链表中紧邻存放(相同key的元素的迭代顺序由实现决定,可以不做保证)
- 哈希表是无序的,不对key进行排序
- 哈希表重新哈希之后元素迭代顺序会发生变化
- 哈希表的实现中,会提供两个函数insert_unique和insert_equal分别来实现unordered_set/unordered_map和unordered_multiset/unordered_multimap(也可通过模板特化来针对唯一key或相同key实现不同的逻辑,提升性能)
数组+单链表的实现介绍
数据结构结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| struct SListNode {
SListNode* next;
SListNode() : next(nullptr) {}
void init() { next = nullptr; }
};
template <typename Key, typename Value, typename ExtractKey, typename Hash = std::hash<Key>, typename KeyEquel = std::equal_to<Key>>
class HashTable {
public:
struct HashNode {
HashNode(): node_before_begin(nullptr), node_finish(nullptr) {}
HashNode(SListNode* b, SListNode* f): node_before_begin(b), node_finish(f) {}
SListNode* node_before_begin;
SListNode* node_finish;
};
ExtractKey get_key_func_;
key_equal key_equal_;
hasher hasher_;
SListNode head_;
float max_load_factor_;
BucketStorage buckets_;
size_type size_;
};
|
insert操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| void insert_node(size_type bucket_idx, SListNode* before, SListNode* first, SListNode* last, size_type count) {
InsertAfter(before, first, last);
buckets_[bucket_idx].insert_node(before, first, last);
incr_size(count);
if (last->next && last == buckets_[bucket_idx].node_finish) {
buckets_[bucket(get_key(Node::Value(last->next)))].node_before_begin = last;
}
}
template <typename... Args>
std::pair<iterator, bool> insert_node(bool unique, const_iterator hint, Args&&... args) {
Node* node = NewNode(std::forward<Args>(args)...);
SListNode* prev = hint.node;
const key_type& key = get_key(Node::Value(node));
size_type bucket_idx = bucket(key);
if (prev && (key_equal_(get_key(Node::Value(prev)), key) || (prev->next && key_equal_(get_key(Node::Value(prev->next)), key)))) {
if (unique) {
DeleteNode(node);
return std::make_pair(iterator(), false);
}
} else {
FindNodeResult result = find_node(key, bucket_idx);
if (unique && result.node) {
DeleteNode(node);
return std::make_pair(iterator(), false);
}
prev = result.before;
}
insert_node(bucket_idx, prev, node);
check_for_rehash(0);
return std::make_pair(iterator(node), true);
}
|
find操作
查找单节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| FindNodeResult find_node(const key_type& key) const {
return find_node(key, bucket(key));
}
FindNodeResult find_node(const key_type& key, size_type bucket_idx) const {
const HashNode& hnode = buckets_[bucket_idx];
if (hnode.empty()) {
return {const_cast<SListNode*>(&head_), nullptr};
}
for (SListNode* prev = hnode.node_before_begin; prev->next != hnode.node_finish->next; prev = prev->next) {
if (key_equal_(key, get_key(Node::Value(prev->next)))) {
return {prev, prev->next};
}
}
return {hnode.node_before_begin, nullptr};
}
|
查找范围
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| std::pair<iterator, iterator> equal_range(bool unique, const key_type& key) {
auto res = find_node(key);
if (!res.node) {
return std::make_pair(iterator(), iterator());
}
if (unique) {
return std::make_pair(iterator(res.node), iterator(res.node->next));
} else {
auto range_res = find_range(key, res.before);
return std::make_pair(iterator(res.node), iterator(range_res.first.node->next));
}
}
std::pair<FindNodeResult, size_type> find_range(const key_type& key, const SListNode* before) const {
std::pair<FindNodeResult, size_type> res = std::make_pair(FindNodeResult(), 0);
res.first.before = const_cast<SListNode*>(before);
while (before->next && key_equal_(key, get_key(Node::Value(before->next)))) {
before = before->next;
++res.second;
}
res.first.node = const_cast<SListNode*>(before);
return res;
}
|
删除操作
删除单个元素的操作相对简单,这里是删除范围的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| iterator erase(const_iterator first, const_iterator last) {
if (first == last) {
return iterator(last.node);
}
const value_type& value = Node::Value(first.node);
size_type bucket_idx = bucket(get_key(value));
SListNode* before = PrevNode(buckets_[bucket_idx].node_before_begin, first.node);
SListNode* prev = before;
while (prev->next != last.node) {
HashNode& hnode = buckets_[bucket_idx];
SListNode* node_end = hnode.node_finish->next;
size_type count = 0;
while (prev->next != node_end && prev->next != last.node) {
prev = prev->next;
++count;
}
erase_node(bucket_idx, before, prev, count);
prev = before;
if (prev->next == last.node) {
break;
}
bucket_idx = bucket(get_key(Node::Value(prev->next)));
}
return iterator(last.node);
}
void erase_node(size_type bucket_idx, SListNode* before, SListNode* last, size_type count) {
if (last->next && last == buckets_[bucket_idx].node_finish) {
buckets_[bucket(get_key(Node::Value(last->next)))].node_before_begin = before;
}
SListNode* first = before->next;
SListNode* next = first->next;
buckets_[bucket_idx].erase_node(before, last);
RemoveAfter(before, last);
incr_size(-count);
while (first) {
next = first->next;
DeleteNode(first);
first = next;
}
}
|
rehash操作
上文已介绍
迭代器实现
可直接使用单链表的迭代器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| struct SListIteratorBase {
using iterator_category = std::forward_iterator_tag;
using Self = SListIteratorBase;
SListNode* node;
SListIteratorBase() : node(nullptr) {}
SListIteratorBase(SListNode* n) : node(n) {}
Self& operator++() {
node = node->next;
return *this;
}
Self operator++(int) {
SListNode* ret = node;
node = node->next;
return Self(ret);
}
bool operator==(const Self& other) const { return node == other.node; }
bool operator!=(const Self& other) const { return node != other.node; }
};
template <typename T, typename Difference = std::ptrdiff_t>
struct SListConstIterator : public SListIteratorBase {
using reference = const T&;
using pointer = const T*;
using difference_type = Difference;
using value_type = T;
using Node = singly_list::SListNodeT<T>;
using Base = SListIteratorBase;
using Self = SListConstIterator;
SListConstIterator(): Base() {}
explicit SListConstIterator(const SListNode* node) : Base(const_cast<SListNode*>(node)) {}
reference operator*() const { return Node::Value(node); }
pointer operator->() const { return std::pointer_traits<pointer>::pointer_to(**this); }
Self& operator++() {
Base::operator++();
return *this;
}
Self operator++(int) {
auto ret = *this;
Base::operator++();
return ret;
}
};
|
迭代器失效
- 无重新哈希:无序关联容器的迭代器和引用除了元素被删除外不会被非法化(包括end迭代器)
- 插入元素导致重新哈希:迭代器(包括end迭代器)非法化,引用有效
无序关联式容器的注意事项
- unordered_map的operator[]可能会新增元素
- 无序关联式容器的元素没有顺序
- 删除元素时注意迭代器失效的问题;代码
unordered_map.erase(it); it++;是错误的
- 无法通过迭代器修改键值,但可以修改unordered_map/unordered_multimap的value值
参考
Last updated: