string概述
string和vector在本质上都是动态数组,当存储的类型是字符类型(如char)时,通常使用string,否则就使用vector
string和vector自动管理动态数组,并自动扩充数组的大小,析构时自动释放内存
string提供了字符串查找,替换等成员函数,方便使用
string实现
string在编程中十分常见,了解字符串的实现很有帮助
为了提高string的性能,一般有三种方式来实现string,有时会对这几种方法相结合
- eager copy,即每次都执行深拷贝
- SSO,即Small String Optimization,较小的字符串在栈中分配内存
- COW,即Copy On Write,写时复制
string的结构
介绍三种实现前,先大致介绍下string的结构
如果按照我们自己的设计,字符串必定包含以下三个数据成员:字符串长度,字符串的容量和字符数组指针
1 | struct StringStorage { |
eager copy
直接深拷贝的方式很容易理解,因为string中保存的是指向堆内存的指针,在复制时,需要执行以下步骤执行深拷贝
- 分配新的内存
- 将字符串的内容复制到新内存
- 设置字符串大小和容量
这种字符串的实现方式,相对简单,比较容易理解,但带来的问题是每次复制都需要分配内存和执行复制的操作,当字符串很大时,会带来性能的问题
1 | StringStorage AllocateMediumStorage() { |
SSO
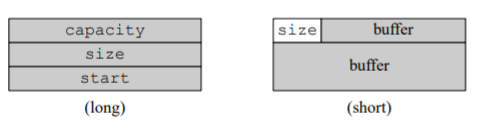
短字符串优化是一个很巧妙的优化方法,利用string本身结构的buffer来存储较小的字符串
上边给出的例子中,至少需要三个变量,因此string的结构本身需要24个字节
当字符串较小时,如果仍在堆上分配内存,但size和capacity本身的值则很小,高位bit都是0,浪费了许多空间
因此在SSO的实现,只用一个字节表示字符串大小,容量大小是固定的,不需要存储,则可以有24-1=23个字节存储字符串,除去尾部的’\0’,则实际的容量为22,这便是llvm/clang/libc++采用的实现
SSO的字符串,复制时只需简单的复制SmallString结构即可,无需在堆上分配内存
另外,他们的实现,会结合SSO、COW和eager copy的实现,因此需要标记字符串的类型,它用一个bit来区分是长字符还是短字符,然后用位操作和掩码 (mask) 来取重叠部分的数据,因此实现是最复杂的。
本文的实现,为了简单,使用一个字节来区分字符串类型
1 | struct SmallString { |
COW
写时复制(Copy-on-write,简称COW)是一种很重要的优化手段。核心思想是懒惰处理多个实体的资源请求,在多个实体之间共享资源,当需要修改时,才真正进行资源的分配
Linux内核在进程fork时对进程地址空间的处理就使用到了COW技术
COW优点
- 减少了分配(和复制)大量资源带来的瞬间延迟(实际上该延迟被分摊到后续的操作中,其累积耗时很可能比一次统一处理的延迟要高,造成throughput下降是有可能的)
- 减少了不必要的资源分配。(例如只读的复制没有必要执行深拷贝)
当然COW不是没有缺点,下文会进行介绍
COW实现
基于COW的思想,我们知道,在string复制时,只进行浅拷贝,而在需要修改对象时,则执行深拷贝的动作。
我们要在什么时候需要执行深拷贝?
- 当前字符串没有被共享,则不需要拷贝
- 当前字符串被共享,当需要修改时,进行深拷贝的动作
因此,为了区分是否被共享,我们引入一个引用计数来记录字符串被多少个string共享
引用计数一般是原子操作,保证线程安全,下文会详细介绍;引用计数需要在堆上分配,保证不同的string对象能够共享
1 | struct LargeString { |
COW在多线程中的问题
像STL的其他容器一样,多线程操作共享的string不是线程安全的。但不同的线程操作不同的字符串是线程安全的。
聪明的同学立马会想到,在COW的string实现中,不同的string对象,可能共享同一块内存,那不同线程同时修改COW实现的string时,怎么保证线程安全呢?
这就要求COW的string必须能够正确的处理这种竞争条件:
- 对引用计数进行原子操作
- 需要修改时,先分配和复制,再将引用计数减1(当引用计数为0时,负责释放内存)
原子操作
比起mutex之类的同步手段,原子操作自然要轻上不少,但比起普通的算术指令,依然算得上完全的重量级
COW为了保证“线程安全”而使用了原子操作,而原子操作本身的效率并不十分高。而且在多线程环境下,多个CPU对同一个地址的原子操作开销更大。COW中”共享“的实现,反而影响了多线程环境下string”拷贝“的性能。
操作顺序
COW中,需要修改时,先分配和复制,再将引用计数减1,这在多线程操作中,会导致不必要的分配和复制
两个线程同时操作两个string,这两个string共享同一片内存(即引用计数为2),当两个线程都需要对string修改时,他们都需要先分配和复制,再将引用计数减1(最终会有一个线程释放内存)
这时,COW一共进行了3次内存分配和复制(初始化时1次,修改时2次)和1次内存释放
但如果没有使用COW技术,从string的初始化到目前为止也只进行了2次内存分配和复制(都是在初始化时进行)
COW的失效问题
这个问题其实是字符串接口导致的问题,string类提供了data、operator[]等接口,可以直接修改字符串本身,但由于他们返回的是指针和引用,只读操作也会导致分配和复制
这可能导致COW不能完全发挥作用,每次都是在深拷贝。
这当然可以通过重新设计接口,严格区分只读和修改造作来解决。但维护非标准接口,并非是一个简单的工作
代理类区分读写操作
区分读写的另一种方式是,定义CharProxy类,operator[]返回CharProxy,在对CharProxy赋值时,才执行分配和复制
但这也会增加编码的复杂度
fbstring
Fackbook的开源库folly中提供了fbstring,它是std::string的替代。其对string类的设计进行了许多优化
- 将字符串区分为small/medium/large,针对他们分别采用SSO、eager copy和COW的策略(使用capacity最高位的4个bits来判断string的种类)
- small:结构体长度为24字节,减去末尾的1字节(用来表示长度)和为结束符’\0’(data()和c_str()方法的需要)预留的1字节,可以放置22字节的有效长度
- medium:不超过255字节
- large:超过255字节
- word-wise copy(逐字拷贝)
- 直接使用malloc/free,并在使用jemalloc时,使用非标准扩展接口来提高性能
- 末尾’\0’的处理:平时预留空间,在调用data或c_str时,才添加’\0’,避免了每次修改字符串时的额外开销
- find使用BM算法

